Rinha de Backend 2026: vetorizando o payload em 14 dimensões
Terceiro artigo da série. A função pura que transforma a transação em um vetor [f32; 14], com parser ISO manual, tabela de MCC hardcoded e os dois exemplos do regulamento como gabarito de teste.
Começando
No post anterior prometi que o próximo seria sobre vetorização. Cumpri o prometido — Slice 2a fechado, PR aberto, 12 testes verdes. Esse artigo é a história de como transformar o JSON da transação em uma lista de 14 números entre 0 e 1, sem inventar nada além do regulamento.
Em termos de algoritmo, é a parte mais simples do projeto. Em termos de risco, a mais ingrata: se eu errar a hora UTC, o dia da semana ou o tratamento do last_transaction: null, os 3 milhões de vetores de referência ficam num sistema de coordenadas e os meus em outro. A busca devolve lixo e eu nunca descubro porque o p99 continua bonito.
Por isso o slice é puxado por testes contra os exemplos do REGRAS_DE_DETECCAO.md. Se bate byte a byte com o doc, bate com o dataset oficial.
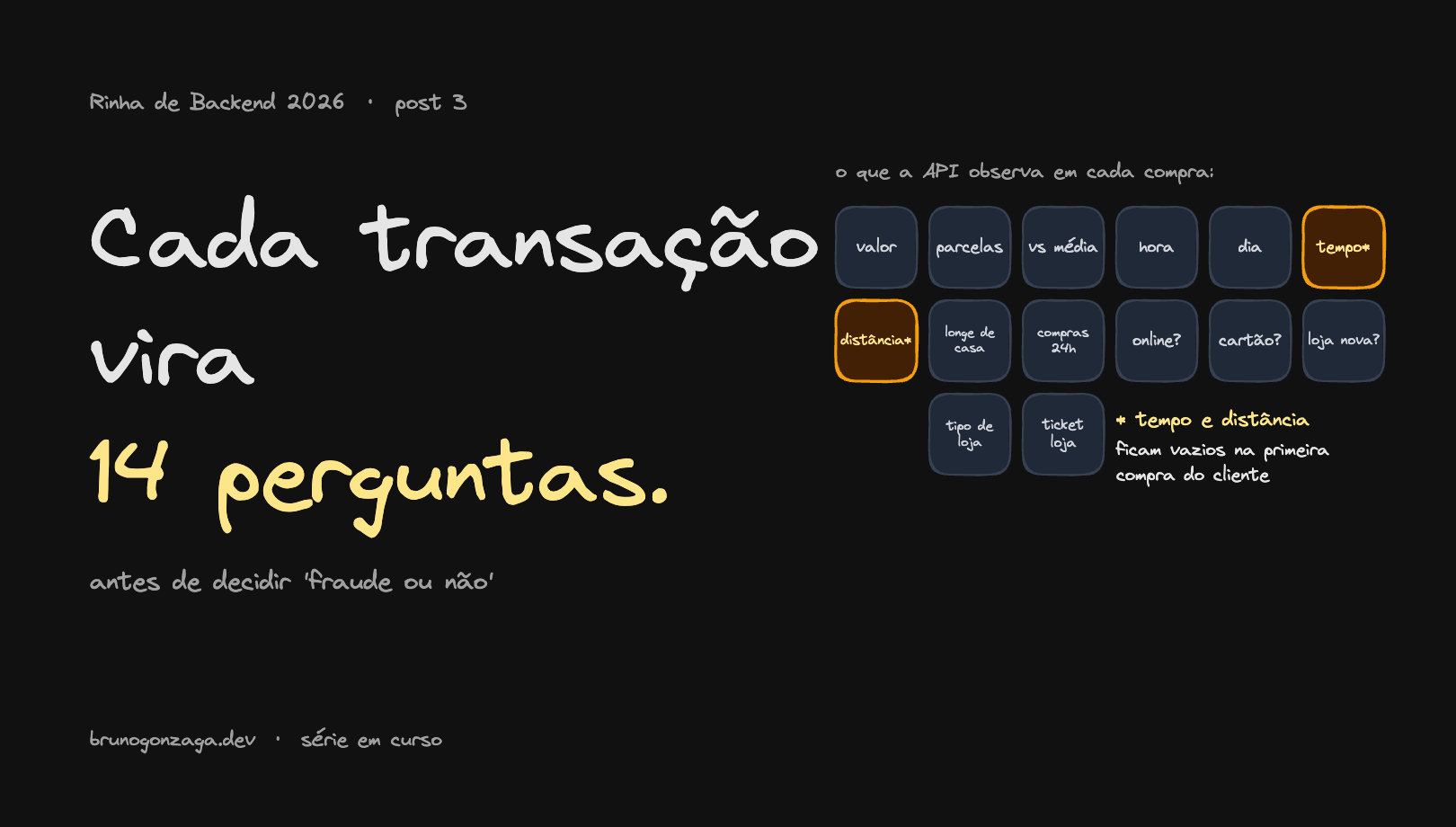
As 14 dimensões

[0,1] — -1 quando last_transaction: null.A ordem é fixa. A normalização também. Tudo está no REGRAS_DE_DETECCAO.md:
| i | dimensão | fórmula |
|---|---|---|
| 0 | amount | clamp(amount / 10000) |
| 1 | installments | clamp(installments / 12) |
| 2 | amount_vs_avg | clamp((amount / customer.avg_amount) / 10) |
| 3 | hour_of_day | hora_utc / 23 |
| 4 | day_of_week | dow / 6 (seg=0 … dom=6) |
| 5 | minutes_since_last | clamp(min / 1440) ou -1 se last_transaction: null |
| 6 | km_from_last | clamp(km_from_current / 1000) ou -1 se last_transaction: null |
| 7 | km_from_home | clamp(km_from_home / 1000) |
| 8 | tx_count_24h | clamp(tx_count_24h / 20) |
| 9 | is_online | bool → 1 |
| 10 | card_present | bool → 1 |
| 11 | unknown_merchant | merchant.id ∉ known_merchants → 1 |
| 12 | mcc_risk | tabela[mcc] ou 0.5 |
| 13 | merchant_avg_amount | clamp(merchant.avg_amount / 10000) |
clamp(x, 0, 1) aparece em quase todas. As dimensões 5 e 6 são a única exceção legal a [0,1] — o sentinela -1 representa “transação anterior inexistente”.
As armadilhas que o regulamento esconde
Lendo o doc rápido você passa por três pegadinhas sem perceber:
Hora dividida por 23, não 24. O exemplo legítimo do doc tem requested_at = 2026-03-11T18:45:53Z e a dimensão 3 sai como 0.7826. Conferindo: 18 / 23 = 0.7826. A interpretação intuitiva (24 buckets de hora) daria 18/24 = 0.75. Errado. O regulamento divide pelo valor máximo da hora (23, porque hora vai de 0 a 23), não pela quantidade de horas no dia.
Convenção segunda=0. A dimensão 4 do exemplo legítimo é 0.3333, e 11/03/2026 é uma quarta. Convenção: seg=0, ter=1, qua=2 → 2/6 = 0.3333. ISO 8601, não a americana com domingo=0. Errar a convenção joga o vetor longe do gabarito sem barulho nenhum.
unknown_merchant é set membership. O campo customer.known_merchants é um array que pode ter duplicatas (["MERC-009", "MERC-009", "MERC-001"] aparece nos exemplos). A dimensão 11 só pergunta se o merchant.id atual está na lista, sem se importar com quantas vezes. Tratei como conjunto.
A função pura
A vectorize é determinística, sem alocação por requisição, e sem Result. Entradas inválidas são barradas pelo serde no handler antes de chegar aqui:
pub fn vectorize(p: &Payload) -> [f32; 14] {
let ts = parse_iso_utc(&p.transaction.requested_at);
let (minutes_since, km_from_last) = match &p.last_transaction {
None => (SENTINEL_NULL, SENTINEL_NULL),
Some(last) => {
let prev = parse_iso_utc(&last.timestamp);
let diff_min = (ts.epoch_seconds - prev.epoch_seconds) / 60;
(
clamp01(diff_min as f32 / MAX_MINUTES),
clamp01(last.km_from_current / MAX_KM),
)
}
};
[
clamp01(p.transaction.amount / MAX_AMOUNT),
clamp01(p.transaction.installments as f32 / MAX_INSTALLMENTS),
clamp01((p.transaction.amount / p.customer.avg_amount) / AMOUNT_VS_AVG_RATIO),
ts.hour as f32 / 23.0,
ts.weekday_mon0 as f32 / 6.0,
minutes_since,
km_from_last,
clamp01(p.terminal.km_from_home / MAX_KM),
clamp01(p.customer.tx_count_24h as f32 / MAX_TX_COUNT_24H),
bool_to_f32(p.terminal.is_online),
bool_to_f32(p.terminal.card_present),
if is_known(&p.merchant.id, &p.customer.known_merchants) { 0.0 } else { 1.0 },
mcc_risk(&p.merchant.mcc),
clamp01(p.merchant.avg_amount / MAX_MERCHANT_AVG_AMOUNT),
]
}Sem JSON I/O em runtime, sem regex, sem chamadas pra chrono. Tudo aritmética em f32 sobre &str e &[u8]. As 14 dimensões saem na ordem do regulamento, posição por posição, na cara.
Decisões pequenas que vão pagar lá na frente
Constantes hardcoded, não lidas de normalization.json. O DATASET.md é explícito: “esses arquivos não mudam durante o teste”. Carregar JSON em runtime só pra ler max_amount = 10000 é incoerente com tudo que decidi no post 2 sobre evitar I/O no caminho quente. Se o organizador alterar, recompila.
Parser ISO manual em vez de chrono. O formato é fixo: YYYY-MM-DDTHH:MM:SSZ, 20 bytes. Escrever parse_u32(&bytes[0..4]) deixa o binário menor, evita uma dependência transitiva grande e não tem risco de o parser aceitar um formato que o organizador não enviou.
fn parse_iso_utc(s: &str) -> Timestamp {
let b = s.as_bytes();
debug_assert!(b.len() == 20 && b[19] == b'Z');
let year = parse_u32(&b[0..4]);
let month = parse_u32(&b[5..7]);
let day = parse_u32(&b[8..10]);
let hour = parse_u32(&b[11..13]);
let minute = parse_u32(&b[14..16]);
let second = parse_u32(&b[17..19]);
Timestamp {
hour,
weekday_mon0: weekday_mon0(year, month, day),
epoch_seconds: epoch_seconds(year, month, day, hour, minute, second),
}
}Sakamoto pro dia da semana. Algoritmo clássico, tabela de 12 inteiros, retorna o dia (sun=0). Converto pra mon=0 com (sun + 6) % 7. Validei contra quatro datas conhecidas, incluindo borda (segunda e domingo).
Hinnant days_from_civil pra diferença de minutos. Quando há last_transaction, preciso da diferença em minutos entre dois timestamps. Em vez de implementar uma calendar library, computo “dias desde 1970-01-01” pelos dois timestamps e subtraio. Algoritmo de Howard Hinnant, sem branch por ano bissexto:
fn days_from_civil(y: i64, m: u32, d: u32) -> i64 {
let y = if m <= 2 { y - 1 } else { y };
let era = y.div_euclid(400);
let yoe = y - era * 400;
let m_adj = if m > 2 { m - 3 } else { m + 9 } as i64;
let doy = (153 * m_adj + 2) / 5 + d as i64 - 1;
let doe = yoe * 365 + yoe / 4 - yoe / 100 + doy;
era * 146_097 + doe - 719_468
}mcc_risk como const &[(&str, f32)] com busca linear. São 10 entradas. Busca linear em 10 elementos com strings curtas vive na L1, é mais rápido que HashMap por causa do hashing + heap. O default 0.5 quando o MCC não consta entra no fallback do loop.
Pausa pra quem não manja de Rust
Se você caiu aqui sem manjar muito de Rust, vou traduzir.
A Rinha 2026 manda transações de cartão pra minha API e pergunta: isso é fraude ou não? O regulamento diz que a forma “oficial” de decidir é:
- Pegar a transação que chegou.
- Transformar ela num vetor — uma lista de 14 números entre 0 e 1 que resumem características (valor, hora, distância de casa, dia da semana, etc.).
- Comparar esse vetor com 3 milhões de vetores de referência guardados.
- Pegar os 5 mais parecidos. Se a maioria deles é fraude, devolvo “fraude”.
O Slice 2a cuidou só do passo 2. Pegar o JSON e transformar nos 14 números.
Cada posição tem um significado:
- Posição 0: o valor é alto? (R$ 41 → 0.0041, R$ 9.505 → 0.95)
- Posição 1: parcelou muito? (2x → 0.16, 10x → 0.83)
- Posição 3: que horas era? (5h da manhã → 0.21, 18h → 0.78)
- Posição 4: dia da semana (segunda → 0, domingo → 1)
- Posições 5 e 6: tempo e distância desde a última compra. Se é a primeira compra do cliente, marca -1 (“não tem dado”).
- Posição 11: o cliente já comprou nesse lugar antes? (1 → lugar desconhecido, mais suspeito)
- Posição 12: o tipo de loja é arriscado? (mercado → 0.15, casa de aposta → 0.85)
A ideia é simples: transações fraudulentas tendem a ter um perfil parecido — valor alto, longe de casa, loja arriscada, hora estranha. Se eu represento cada transação como um ponto num espaço de 14 dimensões, fraudes ficam aglomeradas perto de outras fraudes.
A analogia que uso pra explicar pra não-programadores: imagina que você contratou um estagiário pra fazer só uma coisa — ler o ticket de venda e preencher um formulário de 14 campos com checkboxes e percentuais. Ele não decide nada, só preenche. Depois outra pessoa pega o formulário e compara com milhões de outros pra decidir.
Slice 2a foi ensinar a máquina a preencher esse formulário corretamente, com testes que garantem que ela preenche igualzinho ao gabarito do regulamento.
Os testes são o contrato
O regulamento traz dois exemplos completos: uma transação legítima (tx-1329056812) e uma fraudulenta (tx-3330991687). Cada um vem com o vetor esperado, com 4 casas decimais. Esses dois exemplos viraram fixture inline:
const LEGIT_PAYLOAD: &str = r#"{
"id": "tx-1329056812",
"transaction": { "amount": 41.12, "installments": 2, "requested_at": "2026-03-11T18:45:53Z" },
...
}"#;
#[test]
fn vectorize_legitimate_example_matches_doc() {
let p: Payload = serde_json::from_str(LEGIT_PAYLOAD).unwrap();
let v = vectorize(&p);
let expected = [
0.0041, 0.1667, 0.05, 0.7826, 0.3333, -1.0, -1.0,
0.0292, 0.15, 0.0, 1.0, 0.0, 0.15, 0.006,
];
approx_eq_4dp(&v, &expected);
}O approx_eq_4dp arredonda o f32 pra 4 casas e compara com tolerância 1e-4. Como o doc imprime 4dp, essa é a precisão máxima reportável — tolerância menor seria comparar contra ruído de display, não contra o gabarito.
10 testes ao todo no vector.rs:
vectorize_legitimate_example_matches_doc: fixture legit do doc, byte-equal a 4dp.vectorize_fraud_example_matches_doc: fixture fraude do doc, byte-equal a 4dp.vectorize_last_transaction_null_writes_minus_one_at_5_and_6: sentinela explícita.vectorize_with_last_transaction_computes_minutes_and_km: payload comlast_transactionpreenchido, valida 325 minutos entre dois timestamps reais.clamp_caps_amount_above_max: todas as dimensões comclampsaturam em 1.0.mcc_risk_unknown_returns_default: 0.5 pra “9999” e "".mcc_risk_known_returns_table_value: 0.85 pra 7995, 0.15 pra 5411.unknown_merchant_uses_set_membership_with_duplicates:["MERC-001", "MERC-001"]ainda reconhece “MERC-001”.weekday_matches_known_dates: quatro dias conhecidos cobrindo bordas seg/dom.parse_u32_handles_zero_padded_fields: 00, 05, 23, 2026.
Todos verdes na primeira execução depois que o fixture do legit passou. Cada teste novo me forçou a perguntar “se isso quebrar, qual é o pior caso?”. Set membership com duplicata foi o que eu escrevi rezando porque o doc não é explícito sobre isso. Passou.
Resultado em runtime
http_req_duration: avg=109µs med=76µs p95=220µs max=252µs
checks_succeeded: 100% (20/20)
http_req_failed: 0%Slice 1 marcava p95 218µs. Slice 2a com vetorização real marca p95 220µs. O custo da vetorização + parser ISO + Sakamoto + Hinnant some no ruído de medição. Era esperado: payload pequeno, contas em f32, zero alocação. Mas é satisfatório ver o número.
Edge case: payload mal-formado ({"id": "bad"} sem o resto) volta HTTP 422. O serde corta na entrada do handler. Não preciso validar nada à mão dentro de vectorize.
O que ficou de fora (de propósito)
- Score real (
approved,fraud_score). Continua placeholder. O score só faz sentido depois da busca dos 5 vizinhos, e isso é Slice 3. - Carregar
normalization.jsonem runtime. Decisão consciente. Constantes não mudam. - Otimização SIMD da vetorização. Não é gargalo. O foco do projeto é a busca contra 3M vetores — lá SIMD vale o esforço, aqui não.
- Testes de integração com os 50 payloads de
example-payloads.json. Os payloads de exemplo não vêm com vetor esperado anexado (oexample-references.jsoné dataset separado, não é mapeamento 1:1). Os dois fixtures do regulamento já cobrem o contrato, e expandir pra 50 sem gabarito seria escrever testes que comparam código contra ele mesmo.
Próximo
Slice 2b: o binário preprocess. Vai ler o references.json.gz (16 MB comprimido, 284 MB descomprimido), parsear o stream sem carregar tudo em memória, quantizar cada vetor de f32 pra i16 (decisão fechada no post 2), e escrever três arquivos binários: data/refs.i16.bin, data/labels.bin e data/metadata.json.
Esse binário roda no estágio de build do Dockerfile. A imagem de runtime já recebe os arquivos binários prontos, sem descompactar JSON nem parsear no boot. É lá que a quantização vira artefato.
A vetorização é a parte fácil. A parte difícil é descobrir que ela está errada quando o p99 continua bonito. Por isso o gabarito do regulamento virou suite de teste antes da função existir.
Código completo em obrunogonzaga/rinha-backend-2026-rust. PR do Slice 2a é o #2.