Rinha de Backend 2026: o problema real não é a API
Primeiro artigo da minha jornada na Rinha de Backend 2026. Rust, busca vetorial, 350 MB de memória e o porquê de começar pelo brute force.

Começando
Esse é o primeiro de uma série de artigos sobre como estou encarando a Rinha de Backend 2026. A ideia não é contar a solução perfeita depois que tudo der certo. É mostrar a jornada com os erros, decisões revertidas e os números que aparecem no caminho.
Pra quem não conhece, a Rinha é um desafio organizado pelo Francisco Zanfranceschi onde você sobe sua API em Docker, com limites apertados de CPU e memória, e a engine oficial roda um benchmark unificado contra todo mundo. A graça está nas restrições.
O desafio parece pequeno até você olhar a memória
Na superfície, o contrato da API de 2026 é simples: expor GET /ready e
POST /fraud-score, receber uma transação de cartão e devolver:
{
"approved": false,
"fraud_score": 0.8
}O detalhe é que a decisão não vem de uma regra de negócio comum. Cada payload precisa virar um vetor de 14 dimensões. Depois, a API tem que buscar os 5 vetores mais próximos em um dataset de 3 milhões de referências rotuladas.
O score nasce daí:
fraud_score = fraudes_entre_os_5_vizinhos / 5
approved = fraud_score < 0.6Então a API em si não é o centro do problema. O centro é fazer busca vetorial rápida, com duas instâncias rodando, dentro de 1 CPU e 350 MB somando todos os serviços. O dataset descomprimido sozinho já tem por volta de 284 MB. Se duas APIs carregarem uma cópia da estrutura na memória, o orçamento estoura antes de qualquer linha de lógica.

Por que Rust
Eu escolhi Rust por três motivos, nessa ordem.
Primeiro, é quase pessoal: eu queria sair da zona de conforto. Se a ideia é documentar a jornada, faz sentido escolher uma stack que me obrigue a tomar decisões explícitas sobre layout de memória, alocação e custo de runtime.
Segundo, o problema combina bem com o que Rust entrega de fábrica: binário pequeno, representação compacta e processamento numérico previsível. Rust não resolve nada sozinho, mas reduz a magia entre o código e o que acontece no processo.
Terceiro, e o que mais pesou: o limite de 350 MB não perdoa. Em qualquer linguagem com runtime gordo, eu já começo perdendo orçamento antes de escrever a primeira linha útil.
Eu não forkei o repo oficial
Foi a primeira decisão que me peguei reconsiderando. O caminho mais comum é clonar o repositório oficial e adaptar dali. Eu fui pelo lado oposto: comecei do zero.
A submissão da Rinha aponta para o seu repositório público via
participants/<usuario>.json. Em nenhum lugar pedem fork. Clonar o oficial
traria muitos arquivos que não têm nada a ver com a solução e ia poluir
histórico, branches e CI.
O que eu fiz foi mais cirúrgico: o repo oficial fica como referência. Copio
resources e test quando preciso, mas o código da API mora em um repo
limpo. Primeiro commit no dia 03 de maio:
24661a9 chore: initial project setupJunto, já deixei o agent-md configurado para Codex, Claude Code, Cursor e
Windsurf, com verificações determinísticas no agent-md.toml:
cargo check --locked
cargo fmt --check
cargo clippy --locked --all-targets --all-features -- -D warnings
cargo test --lockedPode parecer overkill para um projeto pessoal. Mas é justamente em projeto pessoal que costuma faltar disciplina. Quero que cada commit já entre com lint e teste passando, sem depender de eu lembrar de rodar.
Antes de pensar em índice sofisticado
A tentação de pular direto para HNSW, IVF, VP-tree ou qualquer ANN é gigante. Mas se eu não tiver um baseline correto, não consigo medir o erro que essas técnicas introduzem. E a Rinha pune erro de detecção com peso real.
Meu plano inicial é mais bobo do que parece:
- Implementar a API mínima e validar o contrato.
- Transformar o payload em vetor de 14 dimensões seguindo os exemplos oficiais.
- Criar uma busca exata simples como baseline local.
- Preprocessar o dataset para um formato binário compacto.
- Comparar qualquer otimização contra o baseline.
O ponto não é vencer com brute force. É usar brute force como verdade local, para saber exatamente o que estou perdendo quando a busca ficar mais esperta.
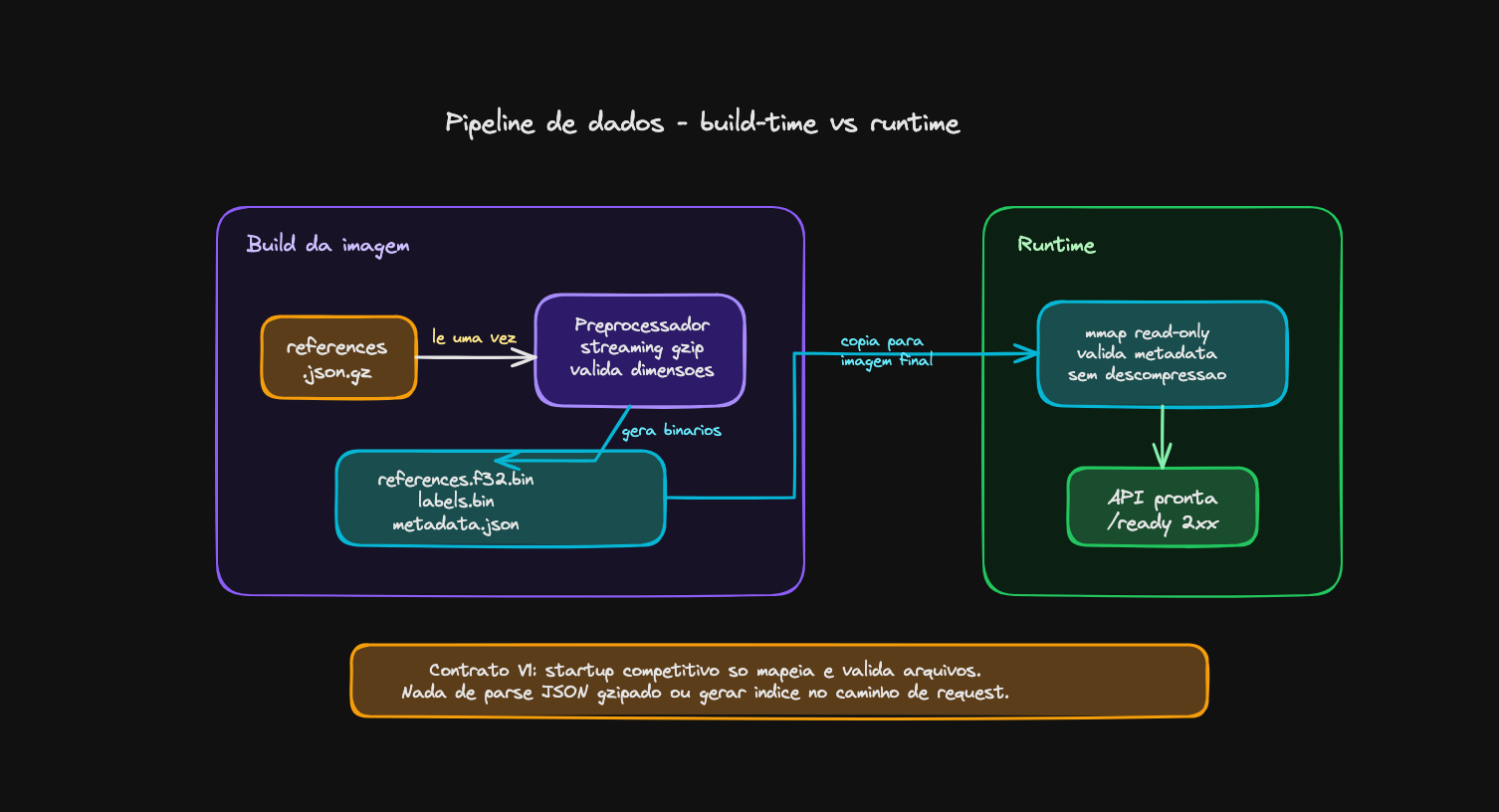
O dataset precisa sair do JSON antes do runtime
O fluxo que eu não quero é este:
startup -> abrir references.json.gz -> descomprimir -> parsear JSON
-> montar estrutura -> atender requestsIsso é ruim para startup, ruim para memória e péssimo para previsibilidade.
Cada serde_json em payload de 284 MB cobra um pedaço do orçamento que eu
não tenho. A direção melhor é empurrar trabalho para build-time:
references.json.gz
-> preprocessador
-> references.f32.bin
-> labels.bin
-> metadata.json
-> runtime com mmapNo caminho competitivo, a API deveria mapear arquivos prontos, validar
metadados e começar a responder. Nada de parsear JSON gigante no caminho
quente. Se der, a versão final usa mmap com float16 ou até quantização
inteira; mas isso fica para depois de medir o brute force em float32.
O erro HTTP custa 5x mais que um falso positivo
Esse foi o número que mudou minha forma de pensar a API. A avaliação tem peso diferente para cada tipo de erro:
| Erro | Peso |
|---|---|
| Falso positivo | 1 |
| Falso negativo | 3 |
| Erro HTTP (5xx, timeout) | 5 |
E tem um cliff: se a soma de FP, FN e erros HTTP passar de 15% das requisições, o score de detecção vai direto para -3000. A latência tem seu próprio cliff: p99 acima de 2000 ms também trava em -3000.
Isso muda completamente a postura de tratamento de falha. Em produção, um payload inválido normalmente vira 4xx. Aqui, na dúvida, devolver:
{ "approved": true, "fraud_score": 0.0 }provavelmente custa menos do que devolver 5xx. Não é bonito e não é uma regra que eu levaria para um produto real. Mas dentro do score, transformar uma falha recuperável em erro de infraestrutura é o pior negócio possível.
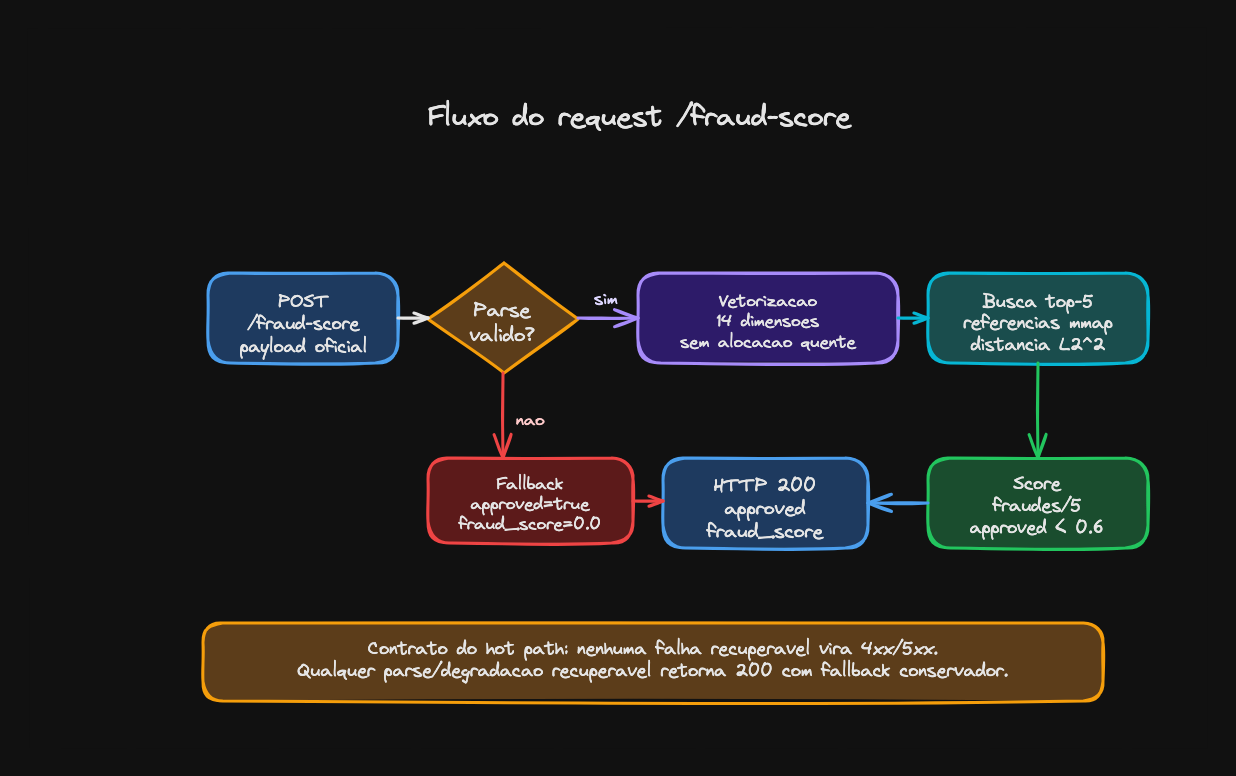
A arquitetura que eu quero defender
Duas APIs, um load balancer fazendo round-robin puro (sem lógica de detecção),
rede bridge, sem host nem privileged. Cada API com acesso local aos
artefatos via mmap. O caminho quente fica assim:
POST /fraud-score
-> parse
-> vetorização 14D (com clamp e MCC default 0.5)
-> top-5 nas referências mapeadas
-> fraud_score
-> HTTP 200Cada seta dessas tem custo. Parse pesa CPU. Vetorização precisa estar correta
até na hora UTC e no last_transaction: null (que vira -1 nos índices 5 e
6). A busca top-k provavelmente vai dominar o p99. E qualquer estrutura
auxiliar precisa caber no mesmo orçamento.
O que vou medir antes de otimizar
| Medida | Por que importa |
|---|---|
| Tamanho dos artefatos preprocessados | Decide se duas APIs cabem em 350 MB |
| Tempo de startup | Afeta confiabilidade do bench |
| Memória por container | Mostra se a arquitetura cabe |
| p99 por versão | Alimenta o score de latência direto |
| FP, FN e erros HTTP | Mostra se a otimização destruiu detecção |
Cada 10x de melhoria no p99 vale +1000 pontos no score (saturando em +3000
quando p99 <= 1ms). Sem esses números do meu lado, qualquer escolha entre
brute force, IVF ou HNSW vira preferência pessoal.
Onde estou agora
Repositório criado, agent-md rodando, hooks de Git e Codex ativos, CLAUDE.md
sincronizado, working tree limpo. Próximo passo: escolher o runtime HTTP
mínimo em Rust e fechar a Slice 1, com GET /ready, POST /fraud-score
parseando o contrato e um smoke test rodando via k6 run test/smoke.js.
Minha meta nesta fase não é ter a solução perfeita. É ter uma base mensurável:
- contrato da API funcionando;
- vetorização validada contra os exemplos oficiais;
- dataset preprocessado;
- baseline exato para servir de referência;
- scripts de teste reproduzíveis;
- espaço claro para trocar o mecanismo de busca depois.
Com essa base, qualquer otimização vira comparação numérica contra o brute force. Sem ela, é chute.
No próximo artigo: como vetorizar essas 14 dimensões sem errar na hora UTC
nem no last_transaction: null. Depois: o preprocessamento do dataset e o
brute force que vai servir de baseline. Se eu chegar lá, ANN com erro
mensurado.