Rinha de Backend 2026: a matriz que travou as decisões antes do código
Segundo artigo da série. Antes de escrever Rust, a conta de memória eliminou metade das opções: axum como HTTP, quantização i16 obrigatória, preprocess em build-time e brute force SIMD como baseline.

Começando
No primeiro artigo eu falei do desenho — Rust, brute force como baseline, dataset preprocessado, mmap, dois containers, 350 MB. Era plano. E fechei prometendo que o próximo seria sobre vetorização. Não foi. Antes de transformar plano em código, eu sentei e fiz a conta de memória que decidiu metade do projeto.
A conta que matou metade das opções
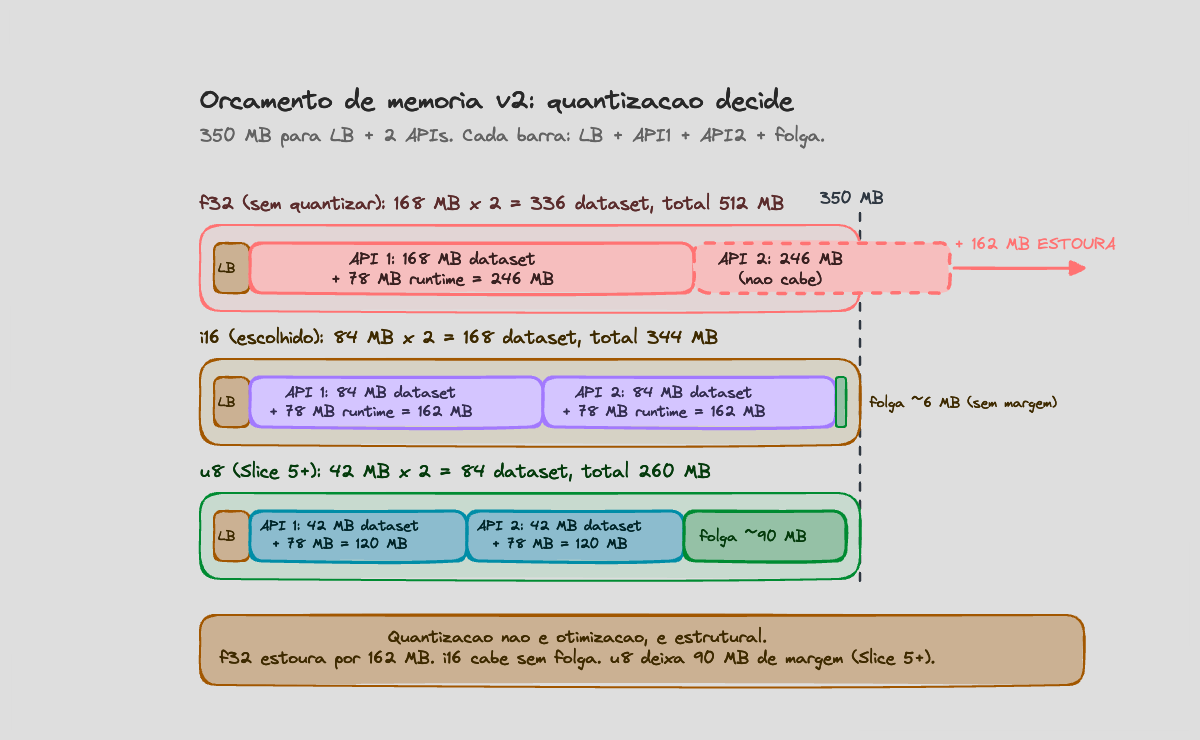
3 milhões de vetores, 14 dimensões, f32 (4 bytes). Por instância:
3_000_000 * 14 * 4 = 168 MBDuas instâncias da API rodando o mesmo dataset:
168 MB * 2 = 336 MBO orçamento total (LB + 2 APIs + tudo) é 350 MB. Sobram 14 MB para nginx, runtime do tokio, parsing JSON, buffers, kernel. Não cabe.
A leitura ingênua é “compartilhar o dataset entre as APIs com mmap”. Funciona em teoria — o page cache do Linux dedupa páginas read-only entre processos. Em cgroup v2, o accounting de páginas mapeadas não é totalmente determinístico, e eu não quero que o sucesso da submissão dependa de quanto o kernel resolveu contar pra cada container. Mmap entra como margem, não como rede de segurança.
Conclusão: quantização não é otimização, é estrutural. Sem reduzir o tamanho de cada vetor, a topologia oficial não cabe.
A matriz de trade-offs
Com a conta acima decidindo a fronteira, o resto virou comparação direta.
HTTP stack
| Opção | Overhead | DX | Risco |
|---|---|---|---|
axum + tokio | sub-ms | alta, é o default | baixo |
actix-web | ~igual | média | baixo |
hyper puro | ~100µs a menos | baixa, muito boilerplate | médio |
pingora / monoio | menor | nicho, manutenção pesada | alto |
Decisão: axum. Se o profiling mostrar que overhead de framework está perto de 1ms no caminho quente, dá pra descer pra hyper puro depois. Começar em hyper por receio é trocar tempo de feature por economia que ainda não foi medida.
Quantização
| Estratégia | RAM/instância | Acurácia | Complexidade |
|---|---|---|---|
f32 (sem quantizar) | 168 MB | exata | trivial — mas não cabe |
i16 | 84 MB | erro estimado ~0,3% | média |
u8 | 42 MB | erro estimado ~1% | média (precisa reservar um valor como sentinela) |
Os números de erro são estimativa de literatura (k-NN com vetores normalizados), não medição. Vou medir contra os fixtures oficiais antes de fechar a quantização no Slice 5+.
i16 é o ponto de equilíbrio: 84 MB × 2 = 168 MB cabe com folga, perda de detecção esperada é pequena, sentinela -1 (do last_transaction: null) mapeia limpa pra -32768. u8 fica como upgrade futuro — como u8 é unsigned, a sentinela vira um valor reservado (255, por exemplo), o que custa um nível de quantização (~0,4%) e exige cuidado pra não colidir com vetores normalizados.
Preprocessamento — build-time vs entrypoint
A pergunta era: descomprimir e quantizar dentro do docker build ou no ENTRYPOINT toda vez que o container subir?
Build-time vence por motivos específicos da Rinha:
- Prévias ilimitadas. O fluxo natural de iteração é abrir muitas issues
rinha/testpra calibrar parâmetros. Cada restart com preprocess no entrypoint custa 5–15s antes do/readyabrir. Build-time = restart instantâneo. - Mac Mini Late 2014. É a casa oficial da Rinha. CPU fraca amplifica o custo de fazer parse JSON + quantização no boot.
- Reprodutibilidade. O
.binquantizado vira parte do hash da imagem. Mesma imagem, mesma latência. Em runtime preprocess sobra variabilidade do parser. - Custo do contra: imagem fica ~80 MB maior. Pull acontece antes do teste começar, fora do scoring. Custo zero pro p99.
Busca
| Estratégia | p99 estimado (i16, scan completo) | Acurácia |
|---|---|---|
| Brute force scalar | 8–15 ms | exata |
| Brute force SIMD (AVX2 no target oficial; NEON no Mac dev) | 3–6 ms | exata |
| VP-Tree (busca exata sublinear) | 1–3 ms | exata |
| HNSW (ANN) | <1 ms | ~99% |
Caminho: brute SIMD primeiro, medir, VP-Tree, medir, ANN só se ainda faltar p99. Cada degrau é uma decisão de trade-off com erro mensurado contra o baseline anterior — exatamente o tipo de comparação que dá ANN com FN sob controle.
O orçamento de memória que defendi
Com i16:
LB (nginx): 20 MB
API1: 165 MB (84 MB vetores i16 + 3 MB labels + ~75 MB runtime)
API2: 165 MB
-------
Total: 350 MB (no limite)Sem folga. Qualquer alocação extra inesperada explode a margem. Por isso o caminho quente da API precisa ser zero-alloc — buffers reusados, sem Vec por request, sem String no JSON parser. Tudo sobre &[u8]. Esse vai ser o primeiro lugar onde o clippy vai brigar comigo.
Slice 1: o endpoint que não faz nada
Com tudo decidido, escrevi o Slice 1 — axum 0.8 com GET /ready e POST /fraud-score retornando placeholder fixo. Sem vetorização, sem busca, nada de fraud logic. O ponto era validar o contrato HTTP e medir o piso do framework.
async fn ready() -> Json<ReadyResponse> {
Json(ReadyResponse { ready: true })
}
async fn fraud_score(_: Json<serde_json::Value>) -> (StatusCode, Json<FraudScoreResponse>) {
(StatusCode::OK, Json(FraudScoreResponse { approved: true, fraud_score: 0.0 }))
}Smoke do k6 contra a binary release, em localhost:
http_req_duration: avg=226µs med=273µs p95=326µs max=339µs
checks_succeeded: 100% (20/20)
http_req_failed: 0%Sem nada acontecendo, o framework cobra ~250µs por request. A meta interna que estabeleci é p99 < 1ms — ali a fórmula de pontuação satura em +3000 e cada 10× de melhoria abaixo disso não rende mais nada. Com axum cobrando 250µs do framework, sobra ~750µs de orçamento pra parsing, vetorização e busca. O artigo anterior dizia que o problema real não era a API. Esse número confirma: tem espaço de sobra pra colocar lógica nele.
O que também é decisão técnica: o setup do repositório
A Rinha exige duas branches no repositório público: main com código-fonte e submission apenas com artefatos de deploy (docker-compose.yml, nginx.conf, info.json). A branch submission aponta pra uma imagem Docker já publicada num registry público.
Eu escolhi:
- Branch
submissionórfã. Sem histórico compartilhado commain. Nada de código-fonte vazando. - Tag-per-slice no GHCR. Cada Slice que passa fim-a-fim vira
ghcr.io/obrunogonzaga/rinha-fraud-rust:v0.X.Y. Asubmissionaponta pra tag específica, não pra:latest. - Prévias amarradas a SHA. Cada execução da Rinha sabe exatamente qual imagem rodou. Reverter é trivial; comparar resultados entre versões é honesto.
A alternativa preguiçosa — montar a submission no fim, com :latest — fecharia o feedback loop. Não dá pra rodar prévia ilimitada se você não consegue voltar pra qualquer versão antiga.
Onde estou agora
PR aberto, Slice 1 mergeado, smoke passando, baseline registrado, repo público com main e submission no ar. Próximo: vetorização das 14 dimensões com fixtures dos exemplos oficiais, sem errar na hora UTC nem no last_transaction: null.
Sem a matriz de trade-offs antes do código, eu provavelmente teria começado pelo HTTP “perfeito” e batido na parede da memória depois. A ordem certa é fazer a conta primeiro, decidir o que cabe, depois codar — mesmo que isso signifique passar uma sessão inteira lendo regulamento e fazendo planilha.
A Rinha é um exercício de orçamento antes de ser um exercício de busca vetorial.