Rinha de Backend 2026: a busca brute force em 3 milhões de vetores
Quinto artigo da série. mmap dos 84 MB de refs.i16.bin, scan completo a cada requisição, top-5 num array de stack, zero alocação no hot path — e o veredito oficial: último lugar, score mínimo, e por que isso era exatamente o plano.

Começando
No post anterior fechei o preprocess: 298 MB de JSON viraram 87 MB de binário i16, prontos pra serem mmap’dos pelo runtime. Bonito de ver, mas isso só é metade do contrato. O regulamento manda usar esses 3 milhões pra decidir se a transação é fraude, e essa decisão sai de uma busca dos 5 vizinhos mais próximos. Esse post é sobre como construir essa busca da forma mais idiota possível — e por que esse ainda é o caminho certo.
A busca brute force — por que começar pelo pior algoritmo
O regulamento manda achar os 5 vetores mais próximos (distância euclidiana, 14 dimensões) e devolver fraud_score = fraudes/5, approved = score < 0.6. Não diz nada sobre como achar esses 5.
A escolha óbvia parecia ser HNSW ou um VP-tree — algoritmos que constroem um índice durante o preprocess e respondem queries em sub-linear. Não foi o que eu fiz. Comecei pelo pior algoritmo possível: scan completo dos 3 milhões a cada request.
Três razões:
- 14 dimensões é território perigoso pra árvores. VP-tree e KD-tree degeneram em alta dimensão. O crossover com brute force fica na faixa de 10–20 dim e depende muito do dataset — pode dar certo, pode dar 0.9× brute force e eu não sabia.
- HNSW tem custo de memória extra (o grafo de vizinhos). Em 350 MB, qualquer overhead conta. Sem medir o brute force primeiro, não dá pra justificar.
- Brute force é o número-teto. Se ele já bate o threshold de p99, acabou. Se não, eu sei exatamente o quanto precisa melhorar e tenho um baseline contra o qual comparar.
Resumindo: medir antes de otimizar é mais barato que otimizar antes de medir.
O loop quente: scalar com auto-vetorização
Não usei std::simd (ainda nightly) nem wide (crate estável de SIMD portável). Usei Rust scalar e deixei o compilador auto-vetorizar. A função de distância:
fn sq_dist_14(q: &[i16; 14], r: &[i16]) -> i64 {
let mut acc: i64 = 0;
for i in 0..14 {
let dx = q[i] as i32 - r[i] as i32;
acc += (dx as i64) * (dx as i64);
}
acc
}Três detalhes que custaram tempo de pensar:
Acumulador i64. Cada dx cabe em i32 (vale entre -20000 e 20000 no pior caso, com sentinela vs. valor máximo). Mas dx² no pior caso é 400_000_000 e o somatório das 14 dimensões chega a 5.6 × 10⁹ — passa o limite do i32 (2.14 × 10⁹). Acumular em i64 fecha a brecha sem pagar nada além de um par de instruções de extensão.
Sentinela -1 não precisa de tratamento especial. Quando last_transaction: null, as dimensões 5 e 6 viram -10000 depois da quantização. Se a query também tem null, dx = 0 e a contribuição é zero — idêntico. Se a query tem valor real e a referência tem null (ou vice-versa), dx fica gigante e a distância explode — exatamente o que se quer (transações com e sem histórico não são “parecidas”). A matemática do regulamento já está embutida no sentinela. Zero branch.
Top-5 com array de stack + arg_max em vez de heap. Manter os 5 menores num heap dinâmico seria O(log 5) por inserção, mas exige alocação. Como K=5 é constante, é mais barato manter dois arrays na pilha e atualizar o índice do máximo a cada substituição:
let mut top_dist = [i64::MAX; 5];
let mut top_lbl = [0u8; 5];
let mut max_idx = 0;
for (idx, chunk) in refs.chunks_exact(14).enumerate() {
let d = sq_dist_14(&qi, chunk);
if d < top_dist[max_idx] {
top_dist[max_idx] = d;
top_lbl[max_idx] = labels[idx];
max_idx = arg_max(&top_dist); // 4 comparações, sem alloc
}
}Tudo isso vive em 45 bytes de pilha: cinco i64 + cinco u8 + um usize. Zero heap por request. No idle, o serviço só guarda o mmap das referências — a estrutura de busca em si some entre requests.
mmap, page cache e o que aparece no RSS
refs.i16.bin é mapeado em memória com memmap2::Mmap::map, não lido pra heap. Por quê?
Dois containers da API rodam no mesmo host (configuração do compose do submission). Se cada um carregasse os 84 MB pra heap próprio, RSS total = 168 MB só de vetores. Mmap muda isso: cada container faz mmap do mesmo arquivo, e o kernel coloca as páginas no page cache — uma área de memória global, compartilhada entre processos.
O que isso significa pro cgroup que limita a stack em 350 MB:
- Heap clássico (
Box<[i16]>): 84 MB × 2 containers = 168 MB de RSS anônimo, conta dobrado. - Mmap shared do mesmo arquivo: 84 MB de page cache, contam uma vez no
memory.currentdo cgroup (cgroup v2 contabiliza file-backed pages no limite, mas só uma vez por arquivo, não por processo).
Isso libera ~84 MB do orçamento pra outras coisas — handlers do tokio, buffers de socket, malloc do serde. Em 350 MB, é a diferença entre folgado e apertado.
O trade-off: a primeira leitura de cada página dá page fault e o kernel materializa a página do disco. No idle isso é insignificante; sob carga inicial, pode dar um warm-up perceptível. Duas mitigações no radar: madvise(MADV_WILLNEED) na carga, ou um for chunk in refs.chunks_exact(14) { black_box(chunk[0]) } artificial pra forçar o fault antes de aceitar tráfego. Vou medir o impacto bruto primeiro antes de complicar.
![Anatomia da busca brute force: query [f32;14] -> quantize i16 -> scan 3.000.000 x 14 i16 (sq_dist, acumulador i64) -> top-5 em array de stack (45 bytes, zero heap) -> fraud_score = fraudes/5. Embaixo, o veredito: 14.237 requests = 707 TP + 841 TN + 0 FP + 0 FN + 12.689 timeouts -> 2 cortes -> -6000.](/images/articles/rinha-backend-2026/cover-post5.png)
Primeiro: a prova de que classifica certo
Subindo o binário release contra os 3M refs de verdade e batendo nos dois exemplos do REGRAS_DE_DETECCAO.md:
$ curl -s -X POST http://localhost:9999/fraud-score -d @legit_example.json
{"approved":true,"fraud_score":0.0}
$ curl -s -X POST http://localhost:9999/fraud-score -d @fraud_example.json
{"approved":false,"fraud_score":1.0}Bate byte a byte com o regulamento. O legítimo cai num cluster de 5 vizinhos todos legit; o fraudulento, num cluster de 5 todos fraud. Score 0.0 e 1.0, decisão correta nos dois. A separação dos clusters no espaço de 14 dimensões existe. Guarda isso — vai importar no fim.
O baseline de laboratório (que não vale nada sozinho)
k6 run test/smoke.js (5 iterações sequenciais, 1 VU, darwin/arm64, release build, sem nginx, sem container, sem 1-CPU limit):
| Métrica | Valor |
|---|---|
| min | 10.02 ms |
| p50 | 10.38 ms |
| p95 | 18.14 ms |
| max | 20.07 ms |
| HTTP failed | 0% |
10 ms pra escanear 3 milhões × 14 dimensões single-thread. Quebrando: são 42 milhões de operações i32 sub → mul → i64 add por request, mais 3 milhões de comparações com o top_dist[max_idx]. No arm64 (NEON), o compilador empacota o loop interno em SIMD por conta própria — dá pra confirmar com cargo asm se quiser ver os mla (multiply-add) vetoriais.
Esse número não vale nada sozinho. Single-VU num M3 com cores sobrando não tem nada a ver com 900 conexões concorrentes num Mac Mini de 2014 dividindo um núcleo entre dois containers. O número que importa só sai da Engine oficial.
O número real — a Engine oficial
Empacotei o binário numa imagem Docker multi-stage (preprocess roda no build, data/*.bin embutido, runtime distroless), publiquei v0.4.0 no GHCR, subi a branch submission com nginx + api1 + api2 nos limites do regulamento e abri a issue rinha/test. A Engine rodou o test/test.js completo no hardware oficial: um Mac Mini Late 2014, i5-4278U (Haswell, 2 núcleos físicos), 8 GB, Ubuntu 24.04, com 1 CPU e 350 MB somados entre os três serviços.
O resultado:
| Métrica | Valor |
|---|---|
| Posição | 211 de 211 (último) |
| final_score | -6000 (piso absoluto) |
| p99 | 2002.11 ms |
| failure_rate | 89.13% |
| HTTP errors | 12689 |
| Falsos positivos | 0 |
| Falsos negativos | 0 |
Último lugar. Score mínimo possível. Os dois cortes da fórmula dispararam juntos: p99 ≥ 2000 ms e taxa de falhas ≥ 15%. Não dá pra ser pior que isso.
E mesmo assim esse é o melhor resultado possível pro que esse post se propôs a provar.
Por que -6000 é uma vitória

Olha de novo as duas últimas linhas: zero falsos positivos, zero falsos negativos. De cada requisição que a API conseguiu responder dentro do timeout, toda decisão de fraude estava certa. O classificador nunca errou. Não é “errou pouco” — é zero, nas duas categorias.
O que matou o score não foi a qualidade da detecção. Foi o relógio. Dos ~14 mil requests que chegaram, 12.689 estouraram o timeout de 2001 ms do k6 e viraram erro HTTP — peso 5 na fórmula, o mais pesado de todos. O p99 cravou exatamente no teto do timeout porque a maioria das respostas simplesmente não chegou a tempo.
Faz todo sentido. Cada request escaneia 42 milhões de operações. Num i5 de 2014 com 0.45 de CPU por container, uma busca leva muito mais que o ~1.1 ms que a rampa de 900 rps exige. As requisições enfileiram, a latência explode, o timeout corta. O algoritmo não está lento por estar errado — está lento porque é O(n) e n são três milhões, por request, num núcleo de uma década atrás.
E não fui só eu. Olha o rodapé do ranking:
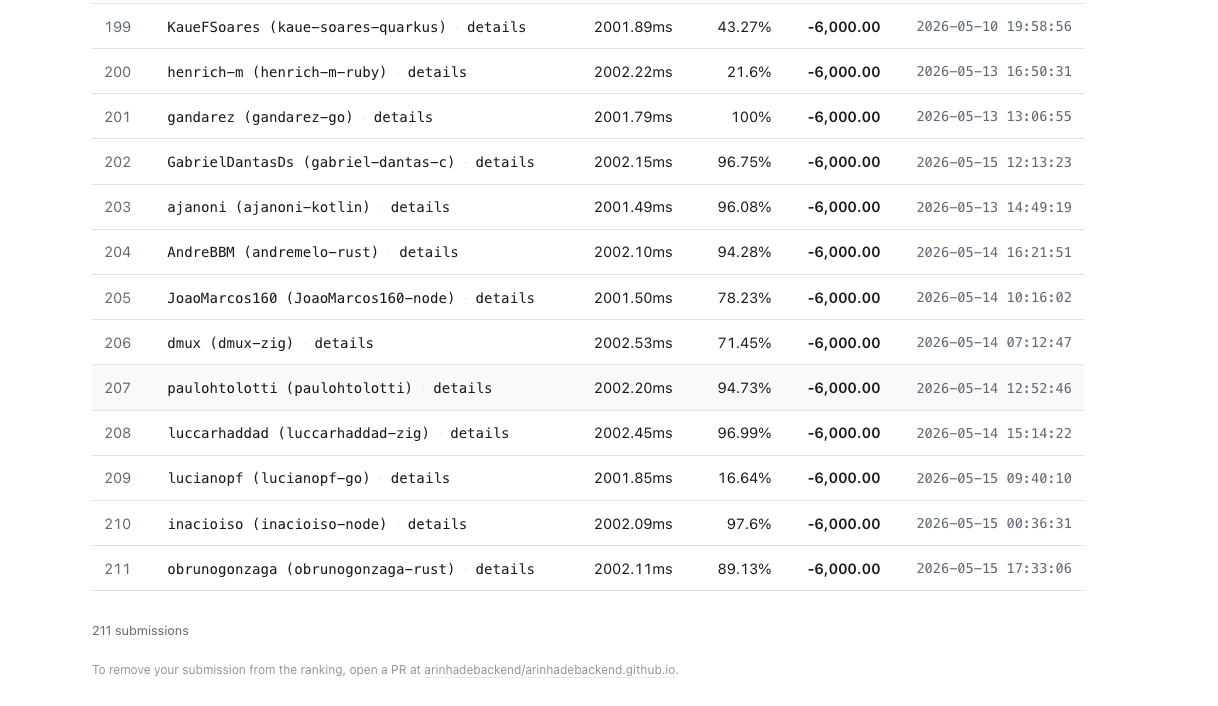
Treze submissões no fundo do poço, com taxas de falha de 16% a 100%, todas com exatamente -6000. O corte de 15% não é uma penalidade proporcional — é um piso plano. Quem não cabe no relógio recebe a mesma nota, seja por pouco ou por muito. O fundo do ranking é onde mora todo mundo que ainda não trocou o algoritmo ingênuo — exatamente onde um baseline brute force deve estar. Estar lá com 0 FP / 0 FN é a forma honesta de estar lá.
Isso é exatamente o que eu disse que ia acontecer lá em cima: “Brute force é o número-teto. Se ele já bate o p99, acabou. Se não, eu sei exatamente o quanto precisa melhorar.” O número chegou. Precisa melhorar muito — e agora eu tenho o baseline contra o qual medir cada otimização.
Medir antes de otimizar não é cautela acadêmica. Sem esse -6000 com 0 FP / 0 FN, eu não saberia se o problema é a busca ou a vetorização. Agora eu sei com certeza absoluta: a vetorização e a regra de decisão estão corretas. O Slice 5 é puramente sobre fazer a mesma busca caber no relógio. Nenhuma das otimizações que vêm por aí toca na lógica de classificação que já provou estar certa.
O que ficou de fora (de propósito)
- SIMD explícito (
std::simd,wide, intrinsics). A auto-vetorização do compilador já entrega o loop em SIMD. Otimização manual antes de ter o número oficial seria chutar no escuro — agora o chute tem alvo. - VP-tree, KD-tree, HNSW. Só compensa se o brute force não fechar o p99 sob carga. Não fechou. Agora compensa.
madvise(WILLNEED)ou pre-warm do mmap. A page fault inicial é ruído perto de um p99 de 2 segundos. Otimizar isso agora seria limpar a casa enquanto ela pega fogo.- Paralelizar o scan entre threads. O tokio já serve várias requests em paralelo; cada request continua single-thread. Dividir o scan dentro de uma request paga fork-join que pode não compensar — mas com 0.45 CPU por container, talvez nem haja thread sobrando pra isso. Fica pro Slice 5 decidir com número na mão.
Próximo
O Slice 5 ataca o -6000 na ordem que a fórmula da Rinha recompensa:
- Derrubar a taxa de falhas pra baixo de 15%. É o corte rígido — enquanto ele dispara, o
detection_scorefica preso em -3000 e nenhum p99 bom compensa. Maior alavanca isolada. - Derrubar o p99 pra baixo de 2000 ms. Cada 10× de latência vale +1000 pontos, até saturar em +3000 com p99 ≤ 1 ms.
Os candidatos — VP-tree (busca exata sublinear), HNSW (aproximada, com olho no FP/FN), quantização pra u8 (metade da banda de memória no scan), SIMD explícito com _mm256_* no lugar da auto-vetorização — entram um de cada vez, cada um medido contra esse -6000. O próximo post abre essa caixa.
O gancho da série inteira já está na tabela: o algoritmo estava certo o tempo todo. Faltava caber no relógio.
Código: github.com/obrunogonzaga/rinha-backend-2026-rust. PR do Slice 3 mergeada em
63b9f34; submissãov0.4.0medida na issue #4586 da Rinha.